BML
BML is the Bubblescript Matching Language. In Bubblescript, BML is
used on various places where user input needs to be matched against a
pattern, for instance in the ask statement.
How does BML work¶
BML is a rule language for matching natural language against a rule base. Think of it as regular expressions for sentences. Whereas regular expressions work on individual characters, BML rules primarily work on a tokenized representation of the string.
Bubblescript's NLP pipeline uses Spacy to tokenize (split) the message into individual sentences and words. This message is then augmented with the output of Duckling to help recognize common entities like dates, numbers, et cetera.
BML can also be used as a standalone Elixir library.
Trying it out¶
An interactive playground / experimentation area for BML is available on bml.dialox.ai. You can try out BML queries there and see how input sentences are tokenized in different languages, and how entities are recognized.

Examples¶
BML patterns are a sequence of rules where each rule in principle is matched against one token in the tokenized version of the sentence. Adjacent rules means that the matching tokens must be adjacent as well; with the exception of punctuation, which is always optional.
Matching basic sequences of words:
| Match string | Example | Matches? |
|---|---|---|
hello world |
Hello, world! | yes |
hello world |
Well hello world | yes |
hello world |
hello there world | no |
hello world |
world hello | no |
Matching regular expressions:
| Match string | Example | Matches? |
|---|---|---|
/[a-z]+/ |
abcd | yes |
Matching literal values:
| Match string | Example | Matches? |
|---|---|---|
hello '.' |
hello. | yes |
hello '.' |
hello | no |
Match entities, with the help of Spacy and Duckling preprocessing and tokenizing the input:
| Match string | Matches | Does not match |
|---|---|---|
[person] |
George Baker | Hello world |
[time] |
I walked to the store yesterday | My name is John |
Where can BML be used in Bubblescript¶
ask¶
In the following dialog we ask someone's date of birth. But they can
also skip the question, either by saying something like "That's
private", or "I don't want to say that".
dialog main do
ask "When were you born?", expecting: "[time] | do not want | private"
if answer.time do
say "The text of what said: " + answer
say "The exact time value: " + answer.time
else
say "Sure, i understand that's private information."
end
end
Note that the NLP processor will correctly adjust the "don't" (conjugation) into the separate tokens "do not" before they are matched.
Dialog triggers¶
Creating a dialog which is triggered on a user utterance is be matched with BML.
dialog trigger: "i be born on? [time]" do
age = date_diff(date_now(), message.time, :years)
say "You are #{age} years old."
end
In this example you can say things like "I was born 18 years ago", "I was born on december 2, 1985", etc.
Intents¶
Intents are defined in the Training section of a bot, and can be defined using a set of BML match patterns.
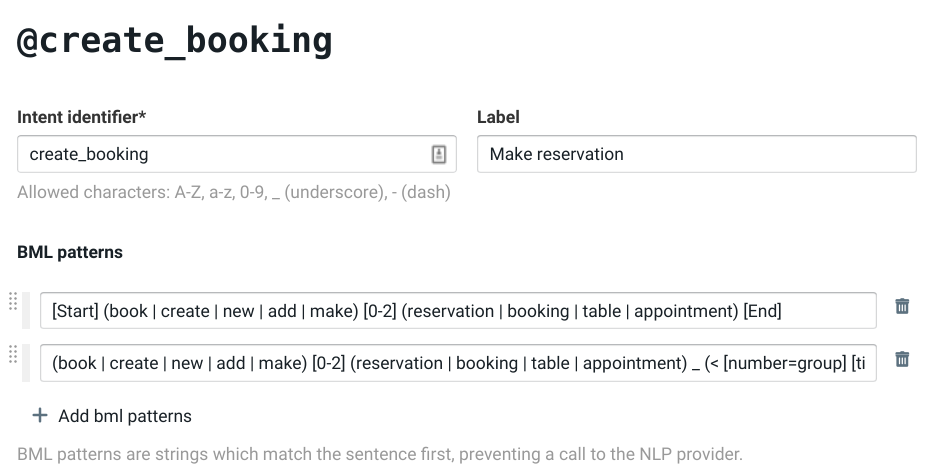
Alternatively, intents can also be defined in Bubblescript code directly. BML patterns can be used there as well:
@born intent(match: "i be born on? [time]")
dialog trigger: @born do
say message.time
end
Rules overview¶
The match syntax is composed of adjacent and optionally nested, rules. Each individual has the following syntax:
Basic words¶
hello world
Basic words; rules consisting of only alphanumeric characters.
Matching is done on both the lowercased, normalized, accents-removed version of the word, and on the lemmatization of the word. The lemma of a word is its base version; e.g. for verbs it is the root form (are → be, went → go); for nouns it is the singular form of the word.
Some languages (german, dutch, …) have compound nouns, that are often
written both with and without spaces or dashes. Use a dash (-) to
match on such compound nouns: the rule was-machine matches all of
wasmachine, was-machine and was machine.
The apostrophe sign is also supported as part of a word, for instance
when matching something like Martha's cookies. In this case, the
apostrophe 's part is called the particle. For places where the
apostrophe is a verb, e.g. in he'll do that, you can write the verb
("will") in full in the BML, as Spacy will determine the proper
verb. In that case, the BML query would be he will do that, which
would also match the version with the apostrophe. Same goes for
don't, he's, etc.
Literals¶
"Literal word sequence"
Matches a literal piece of text, which can span multiple tokens. Matching is case insensitive, and also insensitive to the presence of accented characters.
Ignoring tokens: _¶
hello _ world
The standalone occurrence of _ matches 0-5 of any available token,
non-greedy. This can be used in places where you expect a few tokens
to occur but you don't care about the tokens.
Matching a range of tokens¶
[1]match exactly one token; any token[2+]match 2 or more tokens (greedy)[1-3]match 1 to 3 tokens (greedy)[2+?]match 2 or more tokens (non-greedy)[1-3?]match 1 to 3 tokens (non-greedy)
Use this when you know how many tokens you need to match, but it does not matter what the contents of the tokens is.
Entities¶
Entity tokens: [email] matches a token of type :entity with
value.kind == email. Entities are extracted by external means,
e.g. by an NLP NER engine like Duckling.
Entities are automatically captured under a variable with the same name as the entity's kind.
The default list of supported entities is the following:
amount_of_money(duckling)credit_card_number(duckling)date(spacy)distance(duckling)duration(duckling)email(duckling)event(spacy)fac(spacy)gpe(spacy)language(spacy)law(spacy)loc(spacy)money(spacy)norp(spacy)number(duckling)ordinal(duckling)org(spacy)percent(spacy)person(spacy)phone_number(duckling)product(spacy)quantity(duckling)temperature(duckling)time(duckling)url(duckling)volume(duckling)work_of_art(spacy)
From our experience, Duckling entities work much better than Spacy entities, and are preferred for use. Besides being more accurate, the Duckling entities also provide more metadata, like valid UTC times when a date is recognized.
Regular expressions¶
/regex/
Matches the given regex against the sentence. Regexes can span multiple tokens, thus you can match on whitespace and other token separators. Regular expressions are case insensitive.
Regular expression named capture groups are also supported, to capture
a specific part of a string: /KL(?<flight_number>\d+)/ matches
KL12345 and extracts 12345 as the flight_number capture.
Per-token regular expressions¶
/regex/T
The special regex flag T is used to indicate that the regex should be run
against a single token instead of against the raw text of the sentence.
This will make the regex capturing much more 'narrow'. The regex start and end
symbols (^ and $) are automatically added to the regex, so eg the BML
/\d{4}/T will match the token "1234" but not "12345".
OR / grouping construct¶
Use parentheses combined with the pipe | character to specify an OR clause.
-
pizza | fries | chicken- OR-clause on the root level without parens, matches either token -
a ( a | b | c )- use parentheses to separate OR-clauses; matches one token consisting of firsta, and thena,borc. -
( hi | hello )[=greeting]matches 1 token and stores it ingreeting
Parenthesis with | can also be used to capture a sequence of tokens together as one group:
( a )[3+]matches 3 or more token consisting ofa
Permutation construct¶
The permutation construct using pointy brackets, <, > matches the
given rules in no particular order.
< a b c > matches any permutation of the sequence a b c; a c b, or b a c, or c a b, etc
An implicit _ is inserted between all rules. So the rule <a b> can
also be written as (a _ b | b _ a).
Start / End sentence markers¶
To match the beginning of end of sentences, the following constructs can be used:
[Start]Matches the start of a sentence[End]Matches the end of a sentence
The
[Start]and[End]symbols are not always the same as the start and end of the input string, as sometimes the user input is split into multiple sentences, based on the Spacy sentence tokenizer.
Part-of-speech tags (word kinds)¶
To be able to disambiguate between word kinds, the % construct
matches on the POS-tag of a token:
%VERBmatches any verb%NOUNmatches any noun
Any other POS Spacy tags are valid as well.
Modifiers¶
Capture modifier¶
(my name is _)[=x] stores the entire token sequence "My name is john"
Optionality modifier¶
An appended ? makes the given rule optional (it needs to occur 0 or 1 times).
Repetition modifier¶
Any rule can have a [] block which contains a repetition modifier
and/or a capture expression.
a[1]match exactly oneaworda[2+]match 2 or morea's (greedy)a[1-3]match 1 to 3a's (greedy)a[2+?]match 2 or morea's (non-greedy)a[1-3?]match 1 to 3a's (non-greedy)
Punctuation¶
Punctuation is optional, and can be ignored while creating match rules. However, punctuation tokens are stored in the tokenized version of the input; in fact, multiple tokenizations of the input are stored for each sentence, one without and one with with the punctuation.
The sentence Hello, world. is stored both as:
HelloworldHello,world.
Matching punctuation can be done by including the punctuation into '
literal quotes.